2025. 1. 20.
Workspace 안정화 작업
Work최적화
"지금까지 어떻게 돌아갔을까"
 개발자 윤찬
개발자 윤찬
사내 서비스 중 하나인 workspace는 논코딩 방식으로 AI를 다룰 수 있도록 설계되어 있다. 여러 노드들이 서로 연관된 구조를 가지며, 각 노드는 내부적으로 소켓 통신을 통해 데이터를 주고받는다.
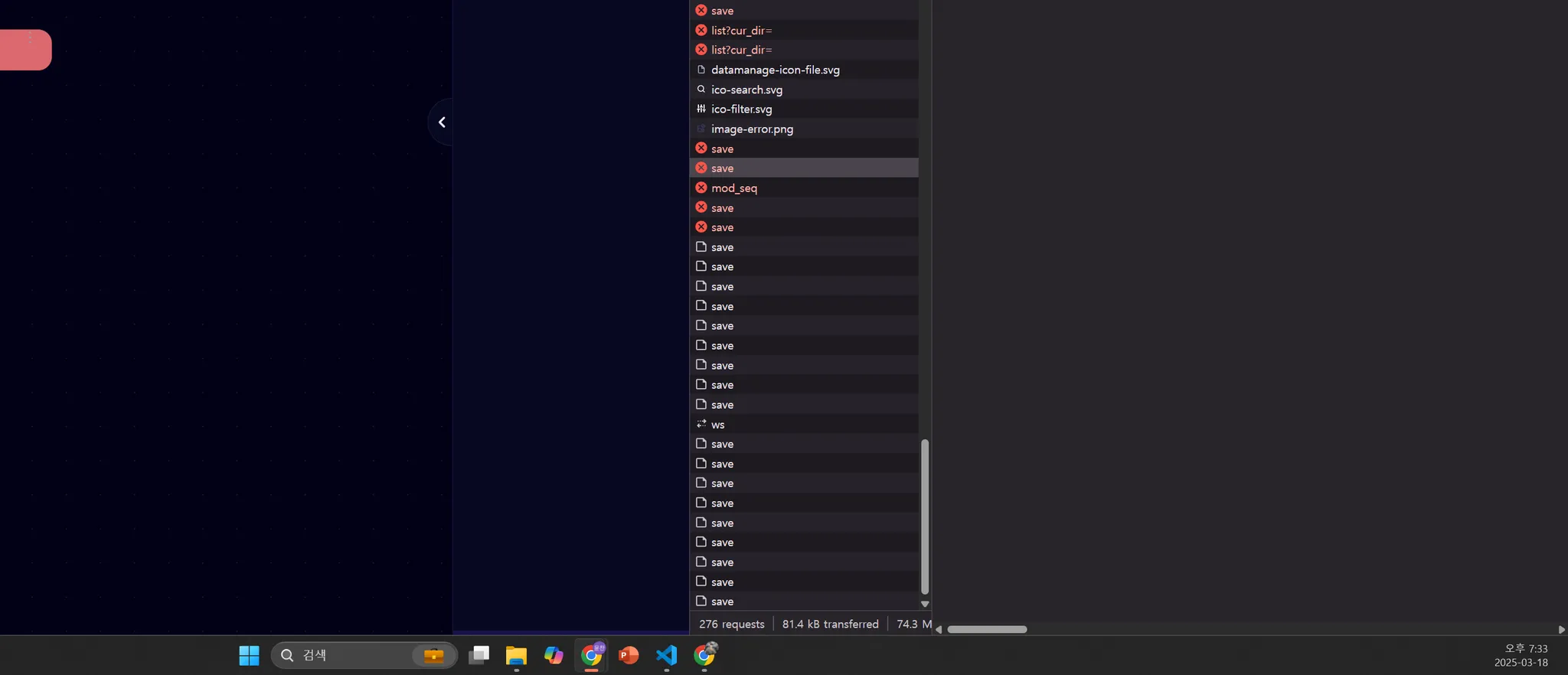
하지만 노드 간 데이터 전달 과정에서 중첩된 렌더링과 API 호출이 반복적으로 발생하고 있었다. 이로 인해 전체 시스템의 성능이 저하되고, 사용자 인터랙션 시 불안정한 동작이 빈번하게 나타났다. 특히 소켓 이벤트가 여러 노드에 중복 전달되면서, 불필요한 렌더링이 트리거되는 문제가 주요 원인이었다.
특히 save 로직에서는 이벤트가 트리거될 때마다 API 호출이 발생하는데, 이 과정에서 서로 연결된 노드들의 렌더링이 모두 pending 상태로 이어지며 순차적으로 처리되는 문제가 있었다. 그 결과 동일한 데이터가 여러 번 저장되는 중복 저장 현상까지 발생하고 있었다.
사실 이러한 방식은 MVP 단계에서는 큰 문제가 되지 않았다. 예를 들어, 5초마다 데이터를 자동 저장하는 polling 방식을 사용하더라도, 서버에서 처리하는 로직이 단순하고 데이터의 크기 또한 크지 않았기 때문에 성능 저하의 가능성은 낮았다.
또한 짧은 주기의 데이터 전송 설정을 통해 실시간 저장이라는 장점도 충분히 살릴 수 있었다. 하지만 이는 어디까지나 API 요청만 놓고 봤을 때의 이야기다. 실제로 이 구조가 Rete 기반의 노드 로직과 얽히게 되면 전혀 다른 문제가 발생한다.
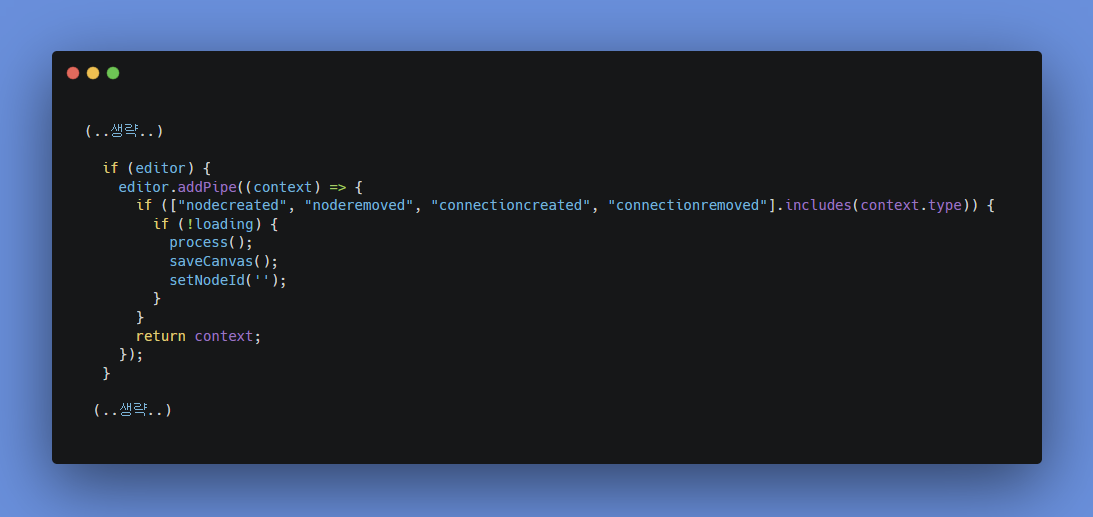
editor에서는 다양한 이벤트에 반응하여 saveCanvas()를 호출하도록 되어있다. 이 이벤트들은 주로 노드 생성, 노드 삭제, 연결 생성, 연결 삭제 등 사용자의 직접적인 인터랙션으로 발생하며, 실시간 반영을 위해 설계된 구조다.
여기서 한 가지 의문을 가질 수 있다. 아래와 같이 saveCanvas()를 유발하는 이벤트 중 moved를 제외하면 실제로 자주 발생하는 것은 아니라는 것이다.
- 노드 생성 (nodecreated)
- 노드 연결 생성 (connectioncreated)
- 노드 연결 제거 (connectionremoved)
서비스의 특성상, 이러한 유저 이벤트가 초단위로 반복해서 발생하는 것은 드물다. 따라서 단순히 5초 간격의 polling 방식으로 API 요청을 처리하고, 그 사이에 실제 변경사항이 있으면 한두 번 정도 추가로 요청이 들어가는 구조라면 큰 문제가 없어 보일 수 있다. 그런데 문제가 발생한 핵심은 다른 곳에서도 있었는데, 우리가 Rete를 커스터마이징하면서 생긴 내부 구조 때문이다.
노드 간 데이터 흐름과 상태 관리를 위해 사용되는 setValue() 함수와, 노드 간 연결을 담당하는 socket 시스템이 얽히면서 예기치 않게 saveCanvas() 호출이 연쇄적으로 발생하게 된 것이다. 특히 setValue() 호출이 소켓을 통해 다시 연결된 노드들을 자극하면서 의도치 않은 순환 호출이 발생했고, 이로 인해 중복 저장, 렌더링 반복, 그리고 예측 불가능한 상태 동기화 문제가 발생하게 되었다.
노드 간 상태 변화가 소켓을 통해 실시간 반영되면서, 단일 이벤트가 여러 노드로 중첩 전달되고, 이는 다시 여러 번의 렌더링 및 저장 요청으로 이어진다. 그 결과, 앞서 언급한 중복 저장, 렌더링 병목, 불필요한 네트워크 요청 등이 한꺼번에 발생하게 된다.
setValue 함수각 노드의 클래스에서는 setValue가 정의되어 있으며, 이 함수는 각 노드에 해당하는 사이드 패널에서 데이터를 받고 저장하거나, 들어오는 값에 대해 초기값을 설정하는 역할을 한다. 또한, 이를 통해 데이터를 외부로 보내거나, 전체 데이터를 관리하는 기능을 수행한다.
socket크게 입력(Input) Socket과 출력(Output) Socket이 있으며, 데이터는 출력에서 입력으로 흐른다. 이 흐름은 단방향으로 적용된다.
이렇게 두 가지 요소와 엮여 save로직에서의 문제를 도식화 해보면
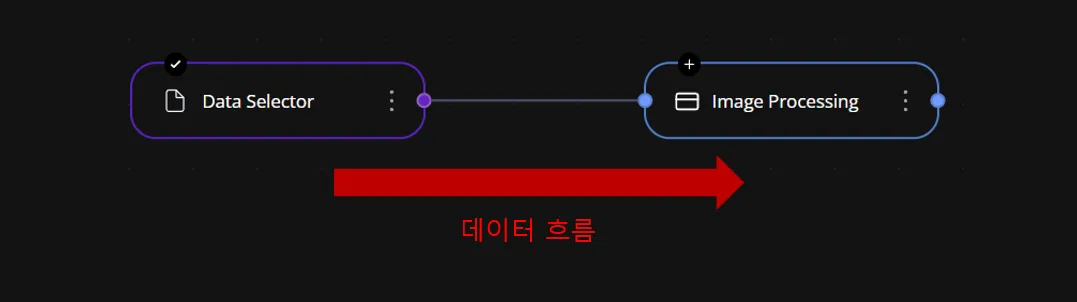
시작노드에서 중간노드(input, output이 모두 있는 노드)로 연결 될 때 시작 노드의 데이터가 중간 노드의 입력으로 전달된다. 그 후, 중간 노드에서 다시 출력이 이루어지고, 해당 출력 값이 다른 노드의 입력으로 들어가며, 이런 방식으로 데이터가 연속적으로 흐르게 된다.
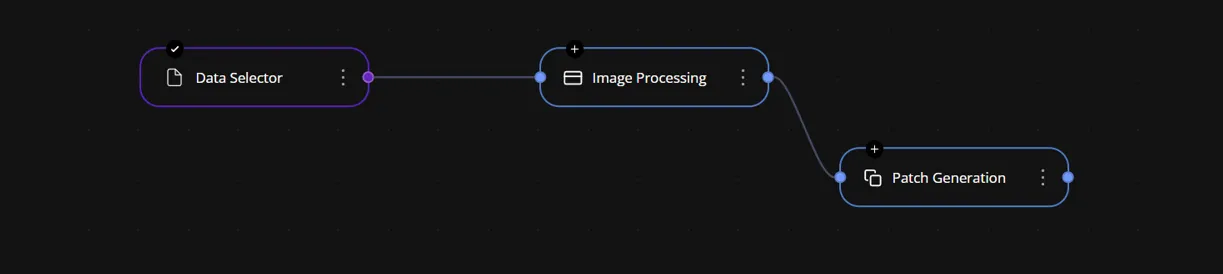
첫 번째 중간 노드에서 초기값을 setValue로 설정하고, 들어온 데이터를 처리한다. 이때 다시 한 번 자신의 setValue를 호출하고, 그 후 저장(save) 로직이 실행되어 데이터가 저장된다.
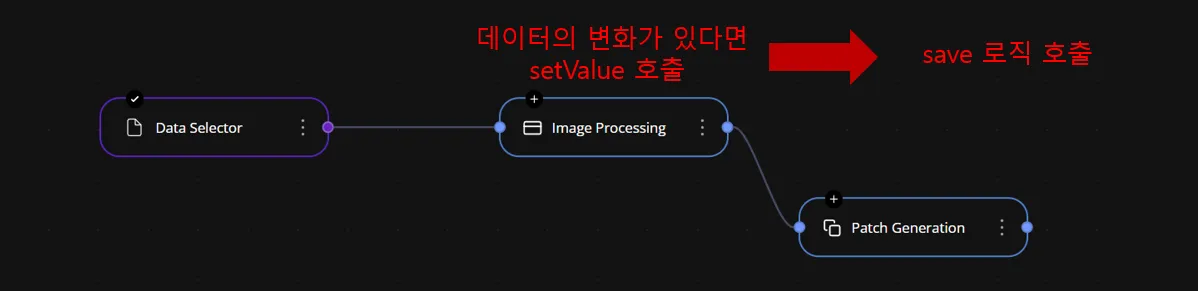
그런 다음, 데이터는 다음 중간 노드로 전달된다. 이때 다음 중간 노드는 받은 데이터를 처리한 후, 자신의 setValue를 호출하고, 다시 저장(save) 로직을 실행한다. 이 과정은 각 노드에서 반복되며, 그로 인해 저장 호출 횟수가 점점 늘어난다.
예를 들어, 하나의 노드에서 setValue와 save가 한 번 호출될 때마다, 다음 노드에서도 setValue와 save가 한 번 더 호출되는데, 이렇게 각 노드가 추가될 때마다 저장 로직의 호출 횟수가 누적되며, 결국 저장 로직은 점차적으로 반복되어 제곱수로 증가하게 된다.
- 1개의 노드에서만 `save`가 호출되면 1번 호출
- 2개의 노드에서 데이터가 처리되면 `save`가 총 4번 호출(각 노드에서 2번 호출)
- 3개의 노드에서 처리되면 `save`가 총 9번 호출(각 노드에서 3번 호출)
따라서, 이렇게 노드를 연결한 파이프라인에서 중간에 데이터가 변경되면, 그 변경된 노드 이후의 노드들에서 다시 한 번 setValue가 실행된다. 그리고, 워크스페이스에서 delete나 create와 같은 작업이 발생할 경우, Rete 엔진을 리셋하는 로직이 실행되어 노드들의 초기값을 다시 설정하기 위해 setValue가 다시 적용된다.
또한, 각 노드들에 대한 최적화가 이루어지지 않은 상태이기 때문에, 만약 사이드 패널에서 init API가 실행되는 기능이 있다면, 리액트의 지역 상태가 변경되고, 이는 데이터 업데이트로 이어져 예기치 않은 문제가 발생할 수 있다. 짜여진 파이프라인에서 간단하게 시작노드를 선택하기만 해도 바로 확인할 수 있었는데,
당시 백엔드 서버는 main 하나에 모든 api요청이 가고 있었기 때문에 다운 될 수 밖에 없었다.
실제 dev 환경에서도 workspace를 작업하다가 save 무한루프? 를 만나게 되면, 모두가 서버를 복구할 때까지 기다렸다.
또한 버전 변경으로 인한 syncFlush 와 종료된 api 호출 그리고 rete engine 초기화 할 때 발생한 동기화 문제 등으로 인해 콘솔까지 열어보면 아래와 같았다.
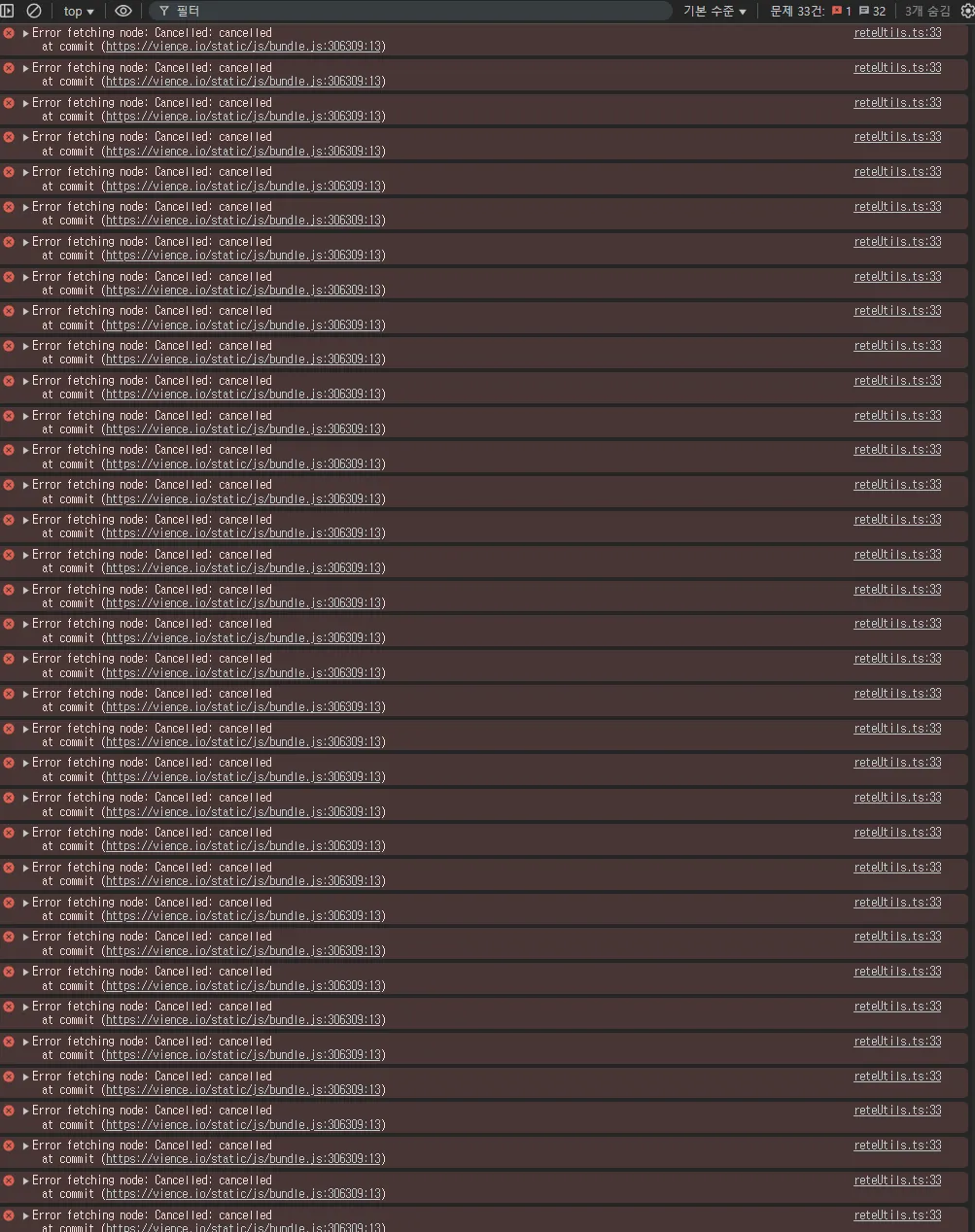
더 재미있는 부분은, 어떤 노드에서 해당 오류가 발생하는지 찾고싶어도 save로직으로 인한 메인서버 멈춤 이슈와, 새로고침을 하면 그 많던 몇 백번의 save요청데도, 저장되지 않고 노드 하나만 남아있는 마법 같은 현상? 때문(해결은 했지만, 언젠가 트러블 슈팅에 언급할 예정)에 브라우저로는 디버깅 조차 불가능한 상황이었다.

일단 접근 전에, 왜 지금까지 workspace의 이러한 부분을 몰랐을까? 하는 궁금증이 들었는데, 그럴 수밖에 없었던 이유는 custom processing, viewer 고도화, patch generation, dataset configuration 외에도 여러 추가되고 리팩토링된 노드들이 복잡한 처리 연산을 수행하고 있었기 때문이다. 이로 인해 문제가 이제 와서 수면 위로 올라온 것이었고, 기존에는 같은 문제라도 사이드 패널에서 작업하는 양 자체가 적었기 때문에 겨우 버티고 있었던 것이었다.
그렇다면 지금 시점(그 당시)으로부터 가장 효율적이면서 해결 할 수 있는 안정 장치가 필요했다.
상황1 : 베타 서비스 발표회 일주일 전
상황2 : QA로 인해 나온 100개가 넘는 다른 버그를 해결해야 하는 상황
각 노드들의 class가 정의되어 있는 부분에서, setValue 로직 자체를 최적화, 그리고 각 sidePanel 최적화
새로 socket을 타고 들어오는 데이터에 대해서, 이전 데이터의 상태와 비교해서 setValue를 중지 시킴
사실 이 방법부터 했는데, canvas안의 캐러셀 컴포넌트부터 진행하는데, 이러다가 언제 다 끝내겠나? 라는 생각이 들었고, 선택과 집중이 필요했다.
가장 문제가 되는 diagram1.component.tsx 즉, save canvas 로직이 있는 파일에서 처리를 하고, 각 노드들에 대해서는 React.memo와 callback 을 둘러 최소한의 최적화 작업이나 안정장치를 수행하는 것
각 패널에서 인자로 받는
ctrl객체(해당 노드의 데이터를 가지고 있음)는 새로 생성되지 않는 한 기존ctrl객체를 계속 사용하기 때문에, 이를 잘 활용하면 불필요한 렌더링을 없앨 수 있었다.
그렇다면 메인인 diagram1.component.tsx 의 로직에서는 debounce와 useCallback을 사용하는 것
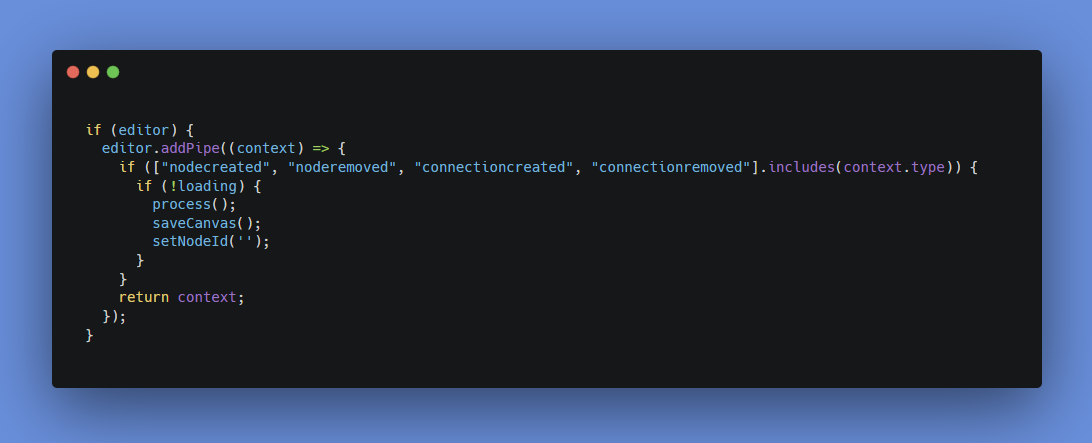
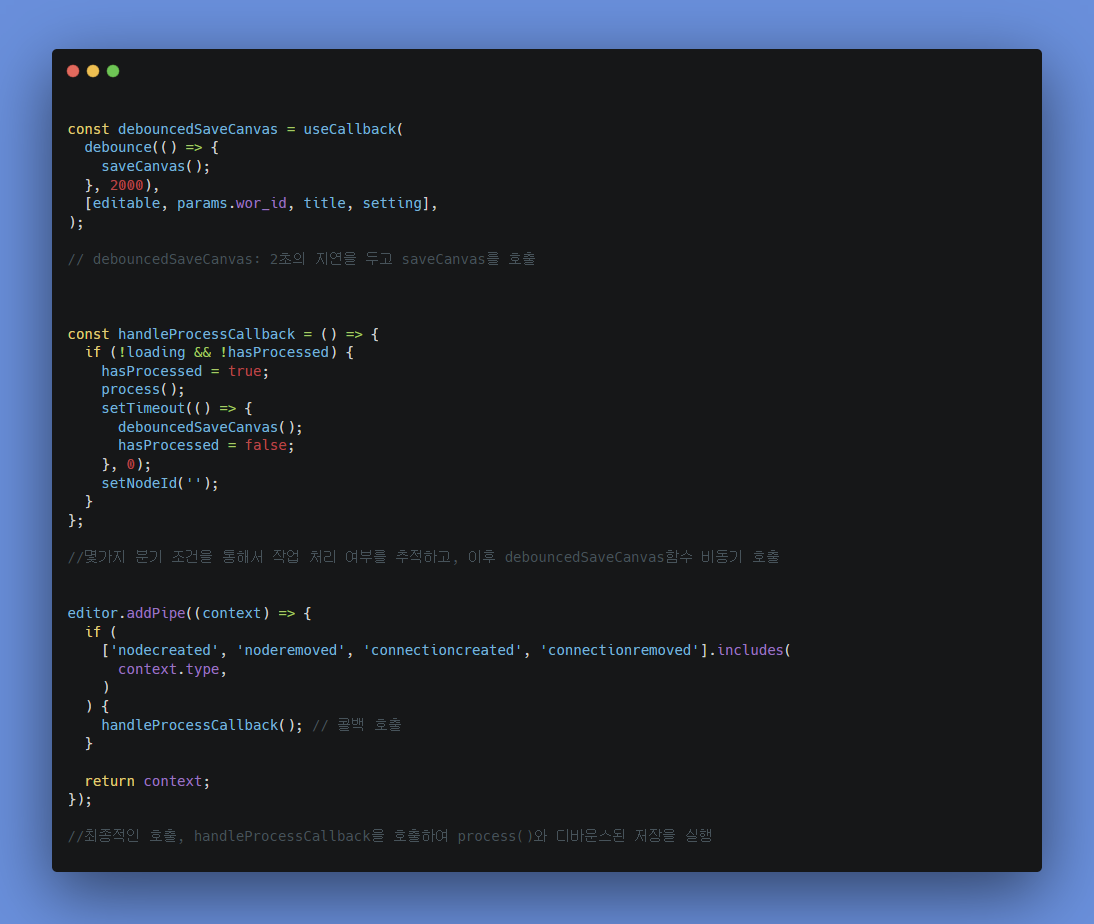
이렇게 하면 저장이 이전의 무한 호출보다는 확실히 덜 처리되기는 하지만, 사용자가 워크스페이스를 나가기 전에 저장이 되지 않을까 걱정되는 문제가 생길 수 있다. 이 문제를 해결하기 위해서는, 워크스페이스를 떠날 때 저장을 강제로 트리거하는 방법이나, 저장이 완료되지 않았을 때 경고 메시지를 표시하는 방법 등을 고려할 수 있었다.
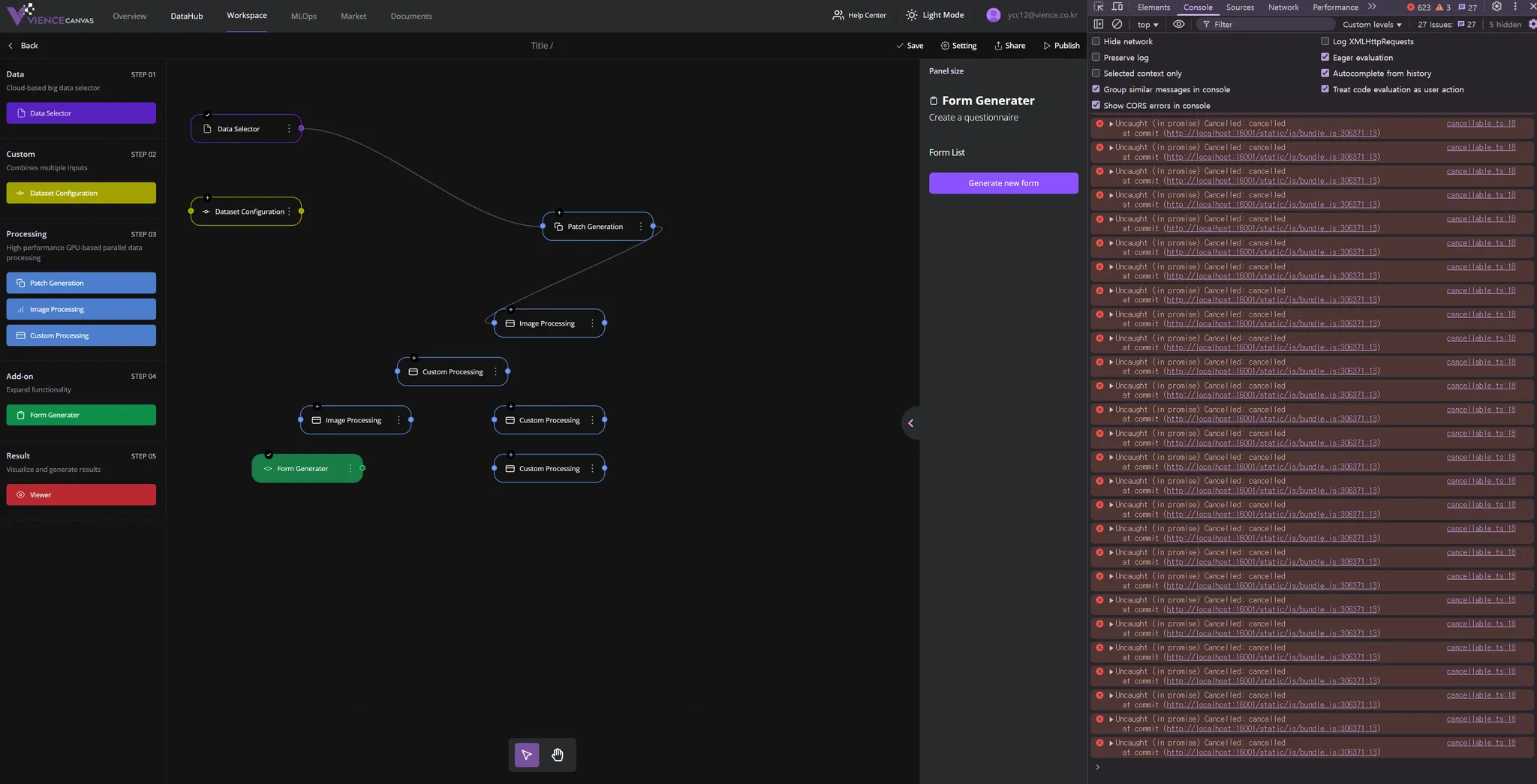
몇 개의 노드 생성과 두개만 연결했는데도, 벌써 오류가 600개 이상 중첩
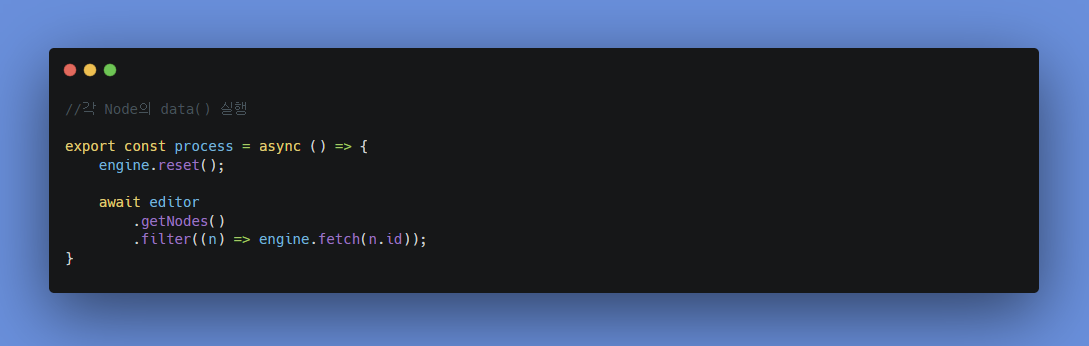
이렇게 engine.reset()을 호출하는 과정에서 editor나 engine의 상태가 초기화되면서 진행 중인 작업이 취소되어 발생하는 오류인데, engine.reset()을 호출하는 과정에서 오류가 발생하는 이유는, reset()이 호출되면 엔진 상태나 편집기 상태가 초기화되어, 이전에 진행 중이던 작업(canvas의 getNode 동작과 filter)이나 상태가 모두 취소되기 때문이다.
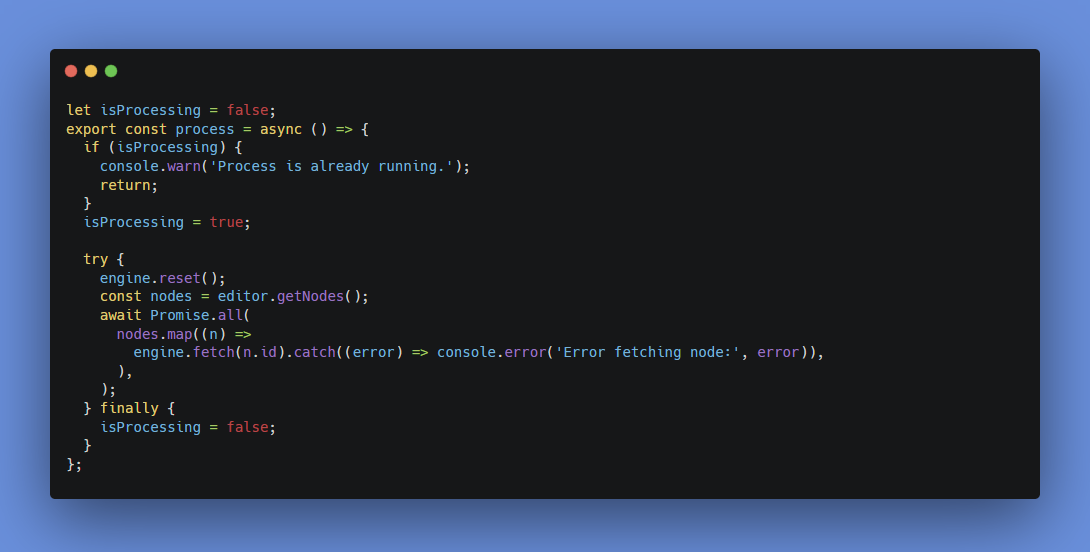
오류를 개별적으로 처리하게 해서 오류가 발생해도, 끊기지 않도록 했고, 변수를 둬서 process의 중복 실행을 막게 하였으며, 이를 Promise.all을 통해서, 그 실행 결과를 모두 기다리게 하여 동작
workspace save로직 최적화 작업
rete 함수 비동기 처리로 내부 오류 해결
각 패널에 대해, 임시로 메모리제이션 적용
https://vience.io/
안정적으로 배포
제곱수 api 호출 및 렌더링을 ⇒ 모두 한 렌더링 주기에 적용
이번 계기로, 생각보다 우리 서비스가 불안했구나 라는게 첫번째 느낀점이다. 그리고, 테코를 포함한 서비스 안정성에 좀더 팀의 초점이 맞춰졌고, 유지보수 측면에서도 많은 지역상태에 대해 일관된 패턴을 적용해야 한다는 생각이 들었다.